Commercial Availability
I recently run into the problem of needing to know on demand whether a compound or reagent is commercially available using only a given name.
A quick search led me to this post by the legendary Jeremy Monat. If you don’t know Jeremy, he is a great cheminformatician, an active contributor to RDKit, and has a very instructive cheminformatics blog. Check it out!
I was able to reuse some of his code (which uses SMILES) and adapt it for my case. I will guide you through the code as we go along, but very briefly, it makes asynchronous calls to PubChem API, finds the CID, and a vendors section. If there is vendors section it assigns a “True” value to an appropriate variable. I have also added code to retrieve the CAS number, and the SMILES, as a means of standardisation and to allow structural verification at the end. Jeremy has a great explanation about asynchronous calls and how they are great for quering long lists of compounds without scaling the time requirements, which I am not going to repeat hear.
First let’s import the appropriate modules:
import asyncio # for async await functionality
import aiohttp # this is better than requests which is my go to and plays nicer with asyncio
from rdkit import Chem #basic rdkit tools
from rdkit.Chem import Draw #drawing of molecules
import json #parse a json object
import pandas as pd #construct dataframes
I have defined a Compound class which get’s a name and has some attributes with default values. These attributes can be populated later with the asynchronous calls to the PubChem API. I have also added a str method to be able to quickly troubleshoot, a .to_dict() method to be able to quickly pass the objects to a pandas dataframe. Make sure to use the “()” when calling the method - speaking from experience…
class Compound():
"""Store a compounds's commercial availability."""
def __init__(self, name: str):
"""
Construct a Coumpound object to store the commercial availability of a compound
:param name: name or synonym for the compound
"""
self._name = name
self._in_pubchem = None
self._cid = None
self._smiles_str = None
self._commercially_available = None
self._pubchem_page = None
self._cas_no = None
@property
def in_pubchem(self):
return self._in_pubchem
@in_pubchem.setter
def in_pubchem(self, value: bool):
""":param value: whether molecule is in PubChem"""
self._in_pubchem = value
@property
def cid(self):
return self._cid
@cid.setter
def cid(self, value: int):
""":param value: PubChem CID (identifier) for molecule"""
self._cid = value
@property
def smiles_str(self):
return self._smiles_str
@smiles_str.setter
def smiles_str(self, value: str):
self._smiles_str = value
@property
def commercially_available(self):
return self._commercially_available
@commercially_available.setter
def commercially_available(self, value: bool):
""":param value: whether molecule is commercially available, per PubChem"""
self._commercially_available = value
@property
def pubchem_page(self):
return self._pubchem_page
@pubchem_page.setter
def pubchem_page(self, value: str):
""":param value: URL or PubChem page for molecule"""
self._pubchem_page = value
@property
def cas_no(self):
return self._cas_no
@pubchem_page.setter
def cas_no(self, value: str):
""":param value: CAS# for compound"""
self._cas_no = value
def __str__(self):
"""User-friendly printout in format:
Compound Name: Phenethyl amine
Compound SMILES: NCCc1ccccc1
in_pubchem: True
CID: 1001
commercially_available: True,
pubchem_page: https://pubchem.ncbi.nlm.nih.gov/compound/1001
CAS #: 64-04-0
"""
str_print = f"Compound Name: {self._name}"
str_print += f"\nCompound SMILES: {self._smiles_str}"
str_print += f"\nin_pubchem: {self._in_pubchem}"
str_print += f"\nCID: {self._cid}"
str_print += f"\ncommercially_available: {self._commercially_available}"
str_print += f"\npubchem_page: {self._pubchem_page}"
str_print += f"\nCAS #: {self._cas_no}"
return str_print
def to_dict(self):
"""Converts the Compound object to a dictionary, suitable for pandas DataFrame."""
return {
"name": self._name,
"in_pubchem": self._in_pubchem,
"cid": self._cid,
"smiles_str": self._smiles_str,
"commercially_available": self._commercially_available,
"pubchem_page": self._pubchem_page,
"cas_number": self._cas_no
}
async def is_commercially_available(name: str) -> Compound:
"""
Asynchronously check the availability of a compound name (chemical) in PubChem.
:param name: A string with the name of the compound.
:returns: A Compound object populated with information from PubChem.
:raises ConnectionError: If there's a failure to connect to PubChem or an HTTP error.
"""
async with aiohttp.ClientSession() as session: # open a session
compound = Compound(name)
# 1. Find the PubChem identifier (CID) for this compound name
get_cid_URL = f"https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/name/{name}/cids/TXT"
cid_str = ""
try:
async with session.get(get_cid_URL, ssl=False) as response: # Consider removing ssl=False in production
response.raise_for_status() # Raise an exception for HTTP errors (4xx or 5xx)
cid_str = (await response.text()).strip()
except aiohttp.ClientResponseError as e: # Catch specific ClientResponseError
if e.status == 404:
# Handle 404 (Not Found) specifically for CID retrieval
print(f"Compound '{name}' not found in PubChem (HTTP 404). Setting attributes accordingly.")
compound._in_pubchem = False
compound._commercially_available = False
compound._cas_no = "N/A" # Ensure CAS is N/A
return compound # Return the unpopulated compound
else:
# For other HTTP errors, re-raise as a ConnectionError
print(f"HTTP error fetching CID for '{name}': {e.status} - {e.message}")
raise ConnectionError(f"Failed to fetch CID from PubChem: {e}")
except aiohttp.ClientError as e:
# Catch other aiohttp client-related errors (e.g., DNS issues, connection reset)
print(f"Aiohttp client error fetching CID for '{name}': {e}")
raise ConnectionError(f"Failed to fetch CID from PubChem: {e}")
except Exception as e:
print(f"An unexpected error occurred fetching CID for '{name}': {e}")
raise
cid = 0
try:
cid = int(cid_str)
except ValueError:
# cid_str was not a valid integer, meaning no CID found
pass
if cid == 0:
compound._in_pubchem = False
compound._commercially_available = False
return compound
else:
compound._cid = cid
compound._in_pubchem = True
compound._pubchem_page = f"https://pubchem.ncbi.nlm.nih.gov/compound/{cid}"
# 2. Get the compound's commercial availability via PubChem's Chemical-Vendors data
# Use 'pug_view' for structured data like XML
compound_vendors_url = f"https://pubchem.ncbi.nlm.nih.gov/rest/pug_view/data/compound/{cid}/XML?heading=Chemical-Vendors"
compound_vendors_response = ""
try:
async with session.get(compound_vendors_url, ssl=False) as response: # Consider removing ssl=False
response.raise_for_status()
compound_vendors_response = await response.text()
except aiohttp.ClientError as e:
print(f"HTTP error fetching vendors for CID {cid}: {e}")
# Continue if vendors data isn't critical, or re-raise
except Exception as e:
print(f"An unexpected error occurred fetching vendors for CID {cid}: {e}")
# Continue or re-raise
if "<Message>No data found</Message>" in compound_vendors_response:
compound.commercially_available = False
else:
compound.commercially_available = True
# 3. Get compound's SMILES string using a more direct endpoint
# This endpoint typically returns just the SMILES string in plain text.
compound_smiles_url = f"https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/cid/{cid}/property/CanonicalSMILES/TXT"
smiles_str_response = ""
try:
async with session.get(compound_smiles_url, ssl=False) as response: # Consider removing ssl=False
response.raise_for_status()
smiles_str_response = (await response.text()).strip()
except aiohttp.ClientError as e:
print(f"HTTP error fetching SMILES for CID {cid}: {e}")
# Continue if SMILES isn't critical, or re-raise
except Exception as e:
print(f"An unexpected error occurred fetching SMILES for CID {cid}: {e}")
# Continue or re-raise
compound.smiles_str = smiles_str_response
# 4. New: Get compound's CAS number
compound_cas_url = f"https://pubchem.ncbi.nlm.nih.gov/rest/pug_view/data/compound/{cid}/JSON?heading=Other-Identifiers"
cas_response = ""
cas_number = None
try:
async with session.get(compound_cas_url, ssl=False) as response:
response.raise_for_status()
cas_response_text = await response.text()
# Check if the response content is empty before attempting to parse JSON
if not cas_response_text.strip():
print(f"Empty response received for CAS data of CID {cid}. Setting CAS to N/A.")
cas_number = "N/A" # Explicitly set to N/A if response is empty
else:
# Parse JSON response only if content is present
data = json.loads(cas_response_text)
# Navigate through the JSON structure based on the provided snippet
cas_data_found = False
# There may be a more efficient way of parsing this JSON...
record = data.get("Record")
if record:
for section_level1 in record.get("Section", []):
if section_level1.get("TOCHeading") == "Names and Identifiers":
for section_level2 in section_level1.get("Section", []):
if section_level2.get("TOCHeading") == "Other Identifiers":
for section_level3 in section_level2.get("Section", []):
if section_level3.get("TOCHeading") == "CAS":
information_list = section_level3.get("Information", [])
if information_list:
first_info = information_list[0]
value_obj = first_info.get("Value")
if value_obj:
string_with_markup_list = value_obj.get("StringWithMarkup", [])
if string_with_markup_list:
first_string_with_markup = string_with_markup_list[0]
cas_string = first_string_with_markup.get("String")
if cas_string:
cas_number = cas_string.strip()
cas_data_found = True
break
if cas_data_found: break
if cas_data_found: break
if cas_data_found: break
if not cas_data_found and cas_number is None: # Only print if CAS was truly not found AND not set to N/A by empty response
print(f"CAS number not found in JSON structure for CID {cid}")
except aiohttp.ClientError as e:
print(f"HTTP error fetching CAS for CID {cid}: {e}")
except json.JSONDecodeError as e:
print(f"JSON decode error for CAS data of CID {cid}: {e}. Response text: '{cas_response_text[:200]}...'") # Log part of response for debugging
except (KeyError, IndexError) as e:
print(f"Error navigating JSON structure for CAS data of CID {cid}: {e}")
except Exception as e:
print(f"An unexpected error occurred fetching CAS for CID {cid}: {e}")
compound._cas_no = cas_number if cas_number else "N/A"
return compound
# Utilities
# To convert from True to Yes, and from False to No, for user-friendly output
boolean_dict = {True: "Yes", False: "No"}
OK. Let’s make sure the above works for a given compound. We need to use the “await” keyword when assigning the variable:
compound = await is_commercially_available("Phenethyl Amine")
print(compound)
Compound Name: Phenethyl Amine
Compound SMILES: C1=CC=C(C=C1)CCN
in_pubchem: True
Cid: 1001
commercially_available: True
pubchem_page: https://pubchem.ncbi.nlm.nih.gov/compound/1001
CAS #: 64-04-0
Great. That works as expected.
Now we need to make it work for more than one compounds. We need to figure out how to set the latency properly so that we do not overwhelm the PubChem API server and get a service denial. That can be done using the “Semaphore” attribute. Check the documentation guidance if you would like to know more.
# Set the number of simultaneous tasks to 2.
# For synchronous (only one task at a time), instead set to 1.
# For fully simultaneous, instead set to greater than or equal to the number of tasks.
sem = asyncio.Semaphore(2)
async def safe_calls(name):
"""Run a limited number of concurrent tasks
Adapted from https://stackoverflow.com/questions/48483348/how-to-limit-concurrency-with-python-asyncio#48486557
:param name: The compound name string
:returns: Class Compound object with information from PubChem
"""
async with sem: # semaphore limits num of simultaneous API calls
return await is_commercially_available(name)
Next we need a way of letting asyncio know that there are a lot of tasks to be done so that it can handle queuing them appropriately. We can use this as an opportunity to remove any duplicates from our list.
async def check_avail_names_set(names_list: list[str]) -> dict[str, Compound]:
"""
Check set of compound names for their availability in PubChem.
:param names_list: List of compound names (representing molecules).
:returns: Dictionary of name:compound pairs, where compound is a Compound object.
"""
#remove duplicates by converting list to set:
names_set = set(names_list)
# Determine commercial availability of each compound
tasks = [asyncio.ensure_future(safe_calls(name)) for name in names_set]
# Note: "A more modern way to create and run tasks concurrently and wait for their completion is
# asyncio.TaskGroup" https://docs.python.org/3/library/asyncio-task.html#asyncio.TaskGroup
# but this was only implemented in Python 3.11, so we use a method that is
# compatible with older versions of Python.
compounds = await asyncio.gather(*tasks) # await completion of all API calls
# Put compounds in dictionary of Name:compound object
names_avail = dict()
for compound in compounds:
names_avail[compound._name] = compound
return names_avail
Now we need a function to make the list of names first into a set to be queried and then returned into a dictionary of compounds assigned to a variable. Notice the use of the “await” keyword again as the “check_avail_names_set” function is an asyncio routine.
async def check_avail_names_list(names_list):
"""Check whether each compound in a list is commercially available.
:param names_list: List of compound names (representing molecules).
:returns: Dictionary of name:compound pairs, where compound is a Compound object.
"""
# When running in Jupyter, use this next line:
names_avail_set = await check_avail_names_set(names_list)
# When running outside Jupyter, use this next line instead:
# smiles_avail = asyncio.run(check_avail_smiles_set(smiles_set))
return names_avail_set
Now let’s define a list of names:
# Check a list of compounds
names_list = ["aspirin", "paracetamol", "acetic anhydride", "EtOAc", "ibuprofen"]
We first need to call our list function - check_avail_names_list, which then calls our set function -check_avail_names_set. Notice again the need to use the “await” keyword.
# When running in Jupyter, use this next line:
names_avail_async = await check_avail_names_list(names_list)
# When running outside Jupyter, use this next line instead:
#smiles_avail = asyncio.run(check_avail_smiles_list(smiles_list))
Now, we have no way of knowing which compound was queried first, second, third as the list to set operation is randomised, and the asyncio routine may also change the order. It’s great that our “check_avail_names_set” function returns a dictionary which we can use to reconstruct our original list.
# Put compounds in same order they were supplied:
# Because check_avail_smiles_list runs asynchronously,
# no guarantee that it will return molecules in same order supplied
names_avail = [names_avail_async[name] for name in names_list]
Now we can do some visualisation to see if the above has worked:
# Create and format molgrid output
mols = [Chem.MolFromSmiles(compound._smiles_str) for compound in names_avail]
legends = [f"Name: {compound._name}"
+ f"\nAvailable: {boolean_dict[compound._commercially_available]}"
+ f"\nCAS #: {compound._cas_no}"
for compound in names_avail]
img = Draw.MolsToGridImage(mols=mols, molsPerRow=2, subImgSize=(300, 300), legends=legends)
img
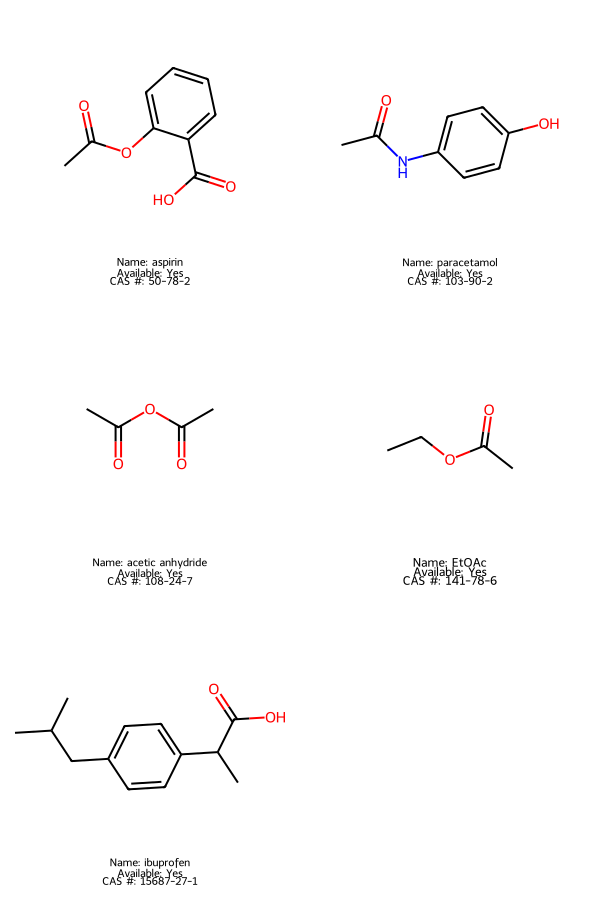
That’s great, but we already knew those where commercially available. What about a more comprehensive list ?
# Get a new list of names
names_list = ["aspirin", "caffeine", "phenethyl amine",
"ethanol", "benzene", "glucose", "NonExistentCompoundXYZ",
"paracetamol", "acetonitrile", "scatole", "indole"]
# Use the same code as above
# When running in Jupyter, use this next line:
names_avail_async = await check_avail_names_list(names_list)
# When running outside Jupyter, use this next line instead:
# smiles_avail = asyncio.run(check_avail_smiles_list(smiles_list))
names_avail = [names_avail_async[name] for name in names_list]
Compound 'NonExistentCompoundXYZ' not found in PubChem (HTTP 404). Setting attributes accordingly.
We immediately see that the ‘NonExistentCompoundXYZ’ was successfully handled and got a notification for it.
Now we can use the compound objects to get a list of dictionaries, and bring them together into a pandas dataframe.
compound_data_for_df = [compound.to_dict() for compound in names_avail]
compounds_df = pd.DataFrame(compound_data_for_df)
compounds_df
| name | in_pubchem | cid | smiles_str | commercially_available | pubchem_page | cas_number | |
|---|---|---|---|---|---|---|---|
| 0 | aspirin | True | 2244.0 | CC(=O)OC1=CC=CC=C1C(=O)O | True | https://pubchem.ncbi.nlm.nih.gov/compound/2244 | 50-78-2 |
| 1 | caffeine | True | 2519.0 | CN1C=NC2=C1C(=O)N(C(=O)N2C)C | True | https://pubchem.ncbi.nlm.nih.gov/compound/2519 | 58-08-2 |
| 2 | phenethyl amine | True | 1001.0 | C1=CC=C(C=C1)CCN | True | https://pubchem.ncbi.nlm.nih.gov/compound/1001 | 64-04-0 |
| 3 | ethanol | True | 702.0 | CCO | True | https://pubchem.ncbi.nlm.nih.gov/compound/702 | 64-17-5 |
| 4 | benzene | True | 241.0 | C1=CC=CC=C1 | True | https://pubchem.ncbi.nlm.nih.gov/compound/241 | 71-43-2 |
| 5 | glucose | True | 5793.0 | C(C1C(C(C(C(O1)O)O)O)O)O | True | https://pubchem.ncbi.nlm.nih.gov/compound/5793 | 50-99-7 |
| 6 | NonExistentCompoundXYZ | False | NaN | None | False | None | N/A |
| 7 | paracetamol | True | 1983.0 | CC(=O)NC1=CC=C(C=C1)O | True | https://pubchem.ncbi.nlm.nih.gov/compound/1983 | 103-90-2 |
| 8 | acetonitrile | True | 6342.0 | CC#N | True | https://pubchem.ncbi.nlm.nih.gov/compound/6342 | 75-05-8 |
| 9 | scatole | True | 6736.0 | CC1=CNC2=CC=CC=C12 | True | https://pubchem.ncbi.nlm.nih.gov/compound/6736 | 83-34-1 |
| 10 | indole | True | 798.0 | C1=CC=C2C(=C1)C=CN2 | True | https://pubchem.ncbi.nlm.nih.gov/compound/798 | 120-72-9 |
The CID is parsed as a float instead of integer type but other than that this is works great.
I hope you have enjoyed this post, and learned something from it, as I had learned from Jeremy’s post.